
Welcome to DD-Ranking (DD, i.e., Dataset Distillation), an integrated and easy-to-use evaluation benchmark for dataset distillation! It aims to provide a fair evaluation scheme for DD methods that can decouple the impacts from knowledge distillation and data augmentation to reflect the real informativeness of the distilled data.
Motivation
Dataset Distillation (DD) aims to condense a large dataset into a much smaller one, which allows a model to achieve comparable performance after training on it. DD has gained extensive attention since it was proposed. With some foundational methods such as DC, DM, and MTT, various works have further pushed this area to a new standard with their novel designs.
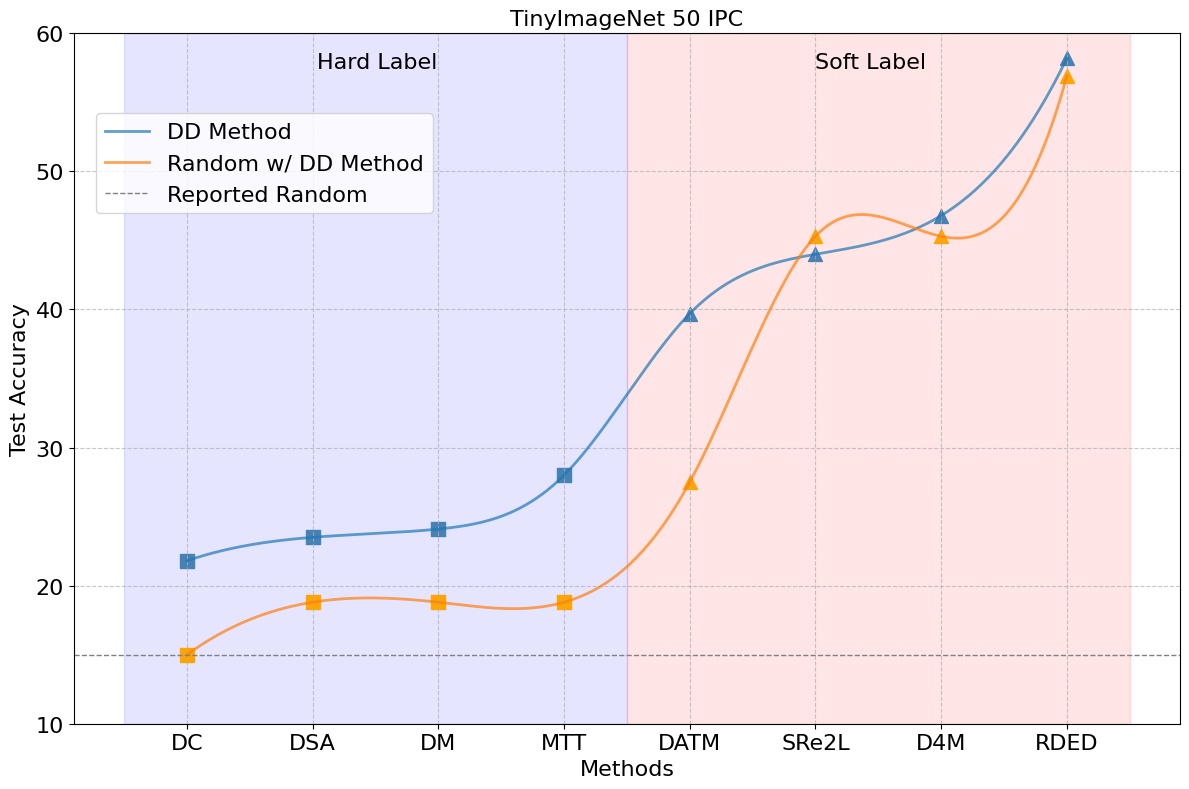
Notebaly, more and more methods are transitting from "hard label" to "soft label" in dataset distillation, especially during evaluation. Hard labels are categorical, having the same format of the real dataset. Soft labels are outputs of a pre-trained teacher model. Recently, Deng et al., pointed out that "a label is worth a thousand images". They showed analytically that soft labels are exetremely useful for accuracy improvement.
However, since the essence of soft labels is knowledge distillation, we find that when applying the same evaluation method to randomly selected data, the test accuracy also improves significantly (see the figure above).
This makes us wonder: Can the test accuracy of the model trained on distilled data reflect the real informativeness of the distilled data?
We summaize the evaluation configurations of existing works in the following table, with different colors highlighting different values for each configuration.
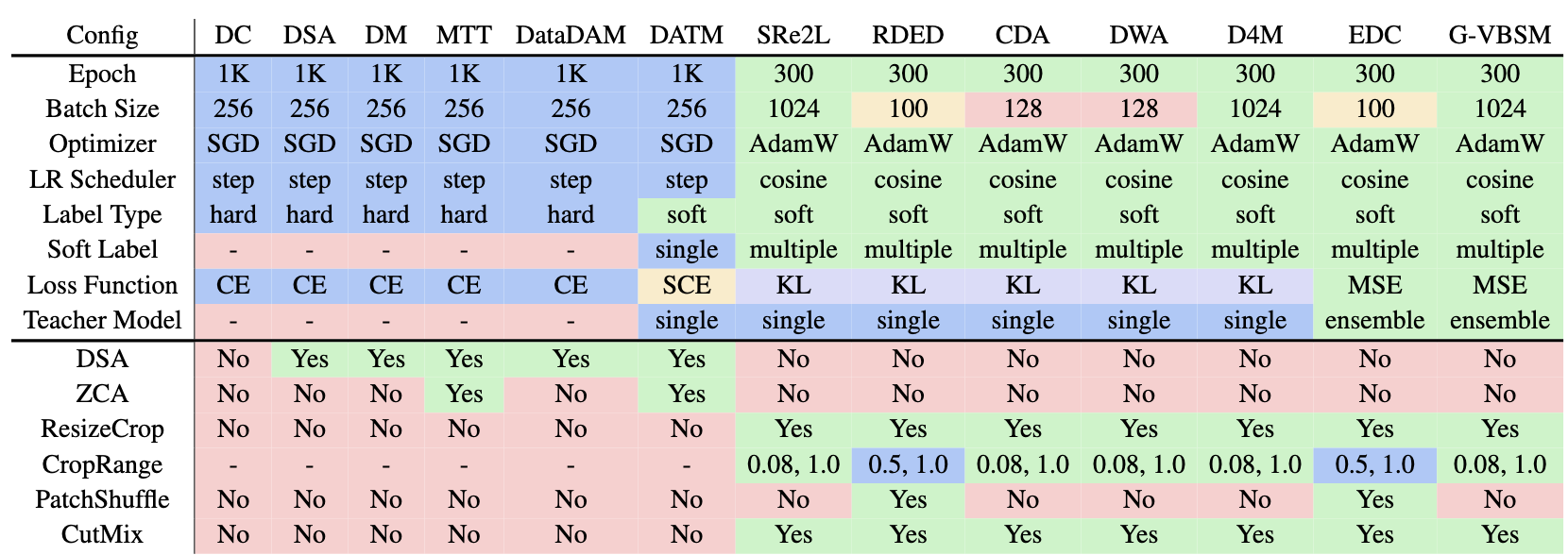 As can be easily seen, the evaluation configurations are diverse, leading to unfairness of using only test accuracy to demonstrate one's performance.
Among these inconsistencies, two critical factors significantly undermine the fairness of current evaluation protocols: label representation (including the corresponding loss function) and data augmentation techniques.
As can be easily seen, the evaluation configurations are diverse, leading to unfairness of using only test accuracy to demonstrate one's performance.
Among these inconsistencies, two critical factors significantly undermine the fairness of current evaluation protocols: label representation (including the corresponding loss function) and data augmentation techniques.
Motivated by this, we propose DD-Ranking, a new benchmark for DD evaluation. DD-Ranking provides a fair evaluation scheme for DD methods that can decouple the impacts from knowledge distillation and data augmentation to reflect the real informativeness of the distilled data.
Features
- Fair Evaluation: DD-Ranking provides a fair evaluation scheme for DD methods that can decouple the impacts from knowledge distillation and data augmentation to reflect the real informativeness of the distilled data.
- Easy-to-use: DD-Ranking provides a unified interface for dataset distillation evaluation.
- Extensible: DD-Ranking supports various datasets and models.
- Customizable: DD-Ranking supports various data augmentations and soft label strategies.
DD-Ranking Benchmark
Revisit the original goal of dataset distillation:
The idea is to synthesize a small number of data points that do not need to come from the correct data distribution, but will, when given to the learning algorithm as training data, approximate the model trained on the original data. (Wang et al., 2020)
Label-Robust Score (LRS)
For the label representation, we introduce the Label-Robust Score (LRS) to evaluate the informativeness of the synthesized data using the following two aspects:
-
The degree to which the real dataset is recovered under hard labels (hard label recovery): \( \text{HLR}=\text{Acc.}{\text{real-hard}}-\text{Acc.}{\text{syn-hard}} \).
-
The improvement over random selection when using personalized evaluation methods (improvement over random): \( \text{IOR}=\text{Acc.}{\text{syn-any}}-\text{Acc.}{\text{rdm-any}} \). \(\text{Acc.}\) is the accuracy of models trained on different samples. Samples' marks are as follows:
- \(\text{real-hard}\): Real dataset with hard labels;
- \(\text{syn-hard}\): Synthetic dataset with hard labels;
- \(\text{syn-any}\): Synthetic dataset with personalized evaluation methods (hard or soft labels);
- \(\text{rdm-any}\): Randomly selected dataset (under the same compression ratio) with the same personalized evaluation methods.
LRS is defined as a weight sum of \(\text{IOR}\) and \(-\text{HLR}\) to rank different methods: \[ \alpha = w\text{IOR}-(1-w)\text{HLR}, \quad w \in [0, 1] \] Then, the LRS is normalized to \([0, 1]\) as follows: \[ \text{LRS} = (e^{\alpha}-e^{-1}) / (e - e^{-1}) \times 100 \% \]
By default, we set \(w = 0.5\) on the leaderboard, meaning that both \(\text{IOR}\) and \(\text{HLR}\) are equally important. Users can adjust the weights to emphasize one aspect on the leaderboard.
Augmentation-Robust Score (ARS)
To disentangle data augmentation’s impact, we introduce the augmentation-robust score (ARS) which continues to leverage the relative improvement over randomly selected data. Specifically, we first evaluate synthetic data and a randomly selected subset under the same setting to obtain \(\text{Acc.}{\text{syn-aug}}\) and \(\text{Acc.}{\text{rdm-aug}}\) (same as IOR). Next, we evaluate both synthetic data and random data again without the data augmentation, and results are denoted as \(\text{Acc.}{\text{syn-naug}}\) and \(\text{Acc.}{\text{rdm-naug}}\). Both differences, \(\text{Acc.syn-aug} - \text{Acc.rdm-aug}\) and \(\text{Acc.syn-naug} - \text{Acc.rdm-naug}\), are positively correlated to the real informativeness of the distilled dataset.
ARS is a weighted sum of the two differences: \[ \beta = \gamma(\text{Acc.syn-aug} - \text{Acc.rdm-aug}) + (1 - \gamma)(\text{Acc.syn-naug} - \text{Acc.rdm-naug}) \] and normalized similarly.
Contributing
Welcome! We are glad that you by willing to contribute to the field of dataset distillation.
-
New Baselines: If you would like to report new baselines, please submit them by creating a pull request. The exact format is below: name of the baseline, code link, [paper link and score run using this tool].
-
New Components: If you would like to integrate new components, such as new model architectures, new data augmentation methods, and new soft label strategies, please submit them by creating a pull request.
-
Issues: If you want to submit issues, you are encouraged to submit yes directly in issues.
-
Appeal: If you want to appeal for the score of your method, please submit an issue with your code and a detailed readme file of how to reproduce your results. We tried our best to replicate all methods in the leaderboard based on their papers and open-source code. We are sorry if we miss some details and will be grateful if you can help us improve the leaderboard.
Installation
From pip
pip install ddranking
From source
python setup.py install
Quick Start
Below is a step-by-step guide on how to use our dd_ranking. This demo is for label-robust score (LRS) on soft labels (source code can be found in demo_lrs_soft.py). You can find the demo for LRS on hard label demo in demo_lrs_hard.py and the demo for augmentation-robust score (ARS) in demo_ars.py.
DD-Ranking supports multi-GPU Distributed evaluation. You can simply use torchrun to launch the evaluation.
Step1: Intialize a soft-label metric evaluator object. Config files are recommended for users to specify hyper-parameters. Sample config files are provided here.
from ddranking.metrics import LabelRobustScoreSoft
from ddranking.config import Config
>>> config = Config.from_file("./configs/Demo_LRS_Soft_Label.yaml")
>>> lrs_soft_metric = LabelRobustScoreSoft(config)
You can also pass keyword arguments.
device = "cuda"
method_name = "DATM" # Specify your method name
ipc = 10 # Specify your IPC
dataset = "CIFAR100" # Specify your dataset name
syn_data_dir = "./data/CIFAR100/IPC10/" # Specify your synthetic data path
real_data_dir = "./datasets" # Specify your dataset path
model_name = "ConvNet-3" # Specify your model name
teacher_dir = "./teacher_models" # Specify your path to teacher model chcekpoints
teacher_model_names = ["ConvNet-3"] # Specify your teacher model names
im_size = (32, 32) # Specify your image size
dsa_params = { # Specify your data augmentation parameters
"prob_flip": 0.5,
"ratio_rotate": 15.0,
"saturation": 2.0,
"brightness": 1.0,
"contrast": 0.5,
"ratio_scale": 1.2,
"ratio_crop_pad": 0.125,
"ratio_cutout": 0.5
}
random_data_format = "tensor" # Specify your random data format (tensor or image)
random_data_path = "./random_data" # Specify your random data path
save_path = f"./results/{dataset}/{model_name}/IPC{ipc}/dm_hard_scores.csv"
""" We only list arguments that usually need specifying"""
lrs_soft_metric = LabelRobustScoreSoft(
dataset=dataset,
real_data_path=real_data_dir,
ipc=ipc,
model_name=model_name,
soft_label_criterion='sce', # Use Soft Cross Entropy Loss
soft_label_mode='S', # Use one-to-one image to soft label mapping
loss_fn_kwargs={'temperature': 1.0, 'scale_loss': False},
data_aug_func='dsa', # Use DSA data augmentation
aug_params=dsa_params, # Specify dsa parameters
im_size=im_size,
random_data_format=random_data_format,
random_data_path=random_data_path,
stu_use_torchvision=False,
tea_use_torchvision=False,
teacher_dir=teacher_dir,
teacher_model_names=teacher_model_names,
num_eval=5,
device=device,
dist=True,
save_path=save_path
)
For detailed explanation for hyper-parameters, please refer to our documentation.
Step 2: Load your synthetic data, labels (if any), and learning rate (if any).
>>> syn_images = torch.load('/your/path/to/syn/images.pt')
# You must specify your soft labels if your soft label mode is 'S'
>>> soft_labels = torch.load('/your/path/to/syn/labels.pt')
>>> syn_lr = torch.load('/your/path/to/syn/lr.pt')
Step 3: Compute the metric.
>>> lrs_soft_metric.compute_metrics(image_tensor=syn_images, soft_labels=soft_labels, syn_lr=syn_lr)
# alternatively, you can specify the image folder path to compute the metric
>>> lrs_soft_metric.compute_metrics(image_path='./your/path/to/syn/images', soft_labels=soft_labels, syn_lr=syn_lr)
The following results will be printed and saved to save_path:
HLR mean: The mean of hard label recovery overnum_evalruns.HLR std: The standard deviation of hard label recovery overnum_evalruns.IOR mean: The mean of improvement over random overnum_evalruns.IOR std: The standard deviation of improvement over random overnum_evalruns.LRS mean: The mean of Label-Robust Score overnum_evalruns.LRS std: The standard deviation of Label-Robust Score overnum_evalruns.
DD-Ranking Metrics
DD-Ranking provides a set of metrics to evaluate the real informativeness of datasets distilled by different methods. The unfairness of existing evaluation is mainly caused by two factors, the label representation and the data augmentation. We design the label-robust score (LRS) and the augmentation robust score (ARS) to disentangle the impact of label representation and data augmentation on the evaluation, respectively.
Evaluation Classes
- LabelRobustScoreHard computes HLR, IOR, and LRS for methods using hard labels.
- LabelRobustScoreSoft computes HLR, IOR, and LRS for methods using soft labels.
- AugmentationRobustScore computes the ARS for methods using soft labels.
- GeneralEvaluator computes the traditional test accuracy for existing methods.
LabelRobustScoreHard
CLASS dd_ranking.metrics.LabelRobustScoreHard(config=None, dataset: str = 'CIFAR10', real_data_path: str = './dataset/', ipc: int = 10, model_name: str = 'ConvNet-3', data_aug_func: str = 'cutmix', aug_params: dict = {'cutmix_p': 1.0}, optimizer: str = 'sgd', lr_scheduler: str = 'step', step_size: int = None, weight_decay: float = 0.0005, momentum: float = 0.9, use_zca: bool = False, num_eval: int = 5, im_size: tuple = (32, 32), num_epochs: int = 300, real_batch_size: int = 256, syn_batch_size: int = 256, use_torchvision: bool = False, eval_full_data: bool = False, random_data_format: str = 'tensor', random_data_path: str = './dataset/', num_workers: int = 4, save_path: Optional[str] = None, custom_train_trans: Optional[Callable] = None, custom_val_trans: Optional[Callable] = None, device: str = "cuda", dist: bool = False ) [SOURCE]
A class for evaluating the performance of a dataset distillation method with hard labels. User is able to modify the attributes as needed.
Parameters
- config(Optional[Config]): Config object for specifying all attributes. See config for more details.
- dataset(str): Name of the real dataset.
- real_data_path(str): Path to the real dataset.
- ipc(int): Images per class.
- model_name(str): Name of the surrogate model. See models for more details.
- data_aug_func(str): Data augmentation function used during training. Currently supports
dsa,cutmix,mixup. See augmentations for more details. - aug_params(dict): Parameters for the data augmentation function.
- optimizer(str): Name of the optimizer. Currently supports torch-based optimizers -
sgd,adam, andadamw. - lr_scheduler(str): Name of the learning rate scheduler. Currently supports torch-based schedulers -
step,cosine,lambda_step, andcosineannealing. - weight_decay(float): Weight decay for the optimizer.
- momentum(float): Momentum for the optimizer.
- step_size(int): Step size for the learning rate scheduler.
- use_zca(bool): Whether to use ZCA whitening.
- num_eval(int): Number of evaluations to perform.
- im_size(tuple): Size of the images.
- num_epochs(int): Number of epochs to train.
- real_batch_size(int): Batch size for the real dataset.
- syn_batch_size(int): Batch size for the synthetic dataset.
- use_torchvision(bool): Whether to use torchvision to initialize the model.
- eval_full_data(bool): Whether to evaluate on the full dataset.
- random_data_format(str): Format of the randomly selected dataset. Currently supports
tensorandimage. - random_data_path(str): Path to the randomly selected dataset.
- num_workers(int): Number of workers for data loading.
- save_path(Optional[str]): Path to save the results.
- custom_train_trans(Optional[Callable]): Custom transformation function when loading synthetic data. Only support torchvision transformations. See torchvision-based transformations for more details.
- custom_val_trans(Optional[Callable]): Custom transformation function when loading test dataset. Only support torchvision transformations. See torchvision-based transformations for more details.
- device(str): Device to use for evaluation,
cudaorcpu. - dist(bool): Whether to use distributed evaluation.
Methods
compute_metrics(image_tensor: Tensor = None, image_path: str = None, hard_labels: Tensor = None, syn_lr: float = None, lrs_lambda: float = 0.5)
This method computes the HLR, IOR, and LRS for the given image and hard labels (if provided). In each evaluation round, we set a different random seed and perform the following steps:
- Compute the test accuracy of the surrogate model on the synthetic dataset under hard labels. We tune the learning rate for the best performance if
syn_lris not provided. - Compute the test accuracy of the surrogate model on the real dataset under the same setting as step 1.
- Compute the test accuracy of the surrogate model on the randomly selected dataset under the same setting as step 1.
- Compute the HLR and IOR scores.
- Compute the LRS.
The final scores are the average of the scores from num_eval rounds.
Parameters
- image_tensor(Tensor): Image tensor. Must specify when
image_pathis not provided. We require the shape to be(N x IPC, C, H, W)whereNis the number of classes. - image_path(str): Path to the image. Must specify when
image_tensoris not provided. - hard_labels(Tensor): Hard label tensor. The first dimension must be the same as
image_tensor. - syn_lr(float): Learning rate for the synthetic dataset. If not specified, the learning rate will be tuned automatically.
- lrs_lambda(float): Weighting parameter for the LRS.
Returns
A dictionary with the following keys:
- hard_label_recovery_mean: Mean of HLR scores from
num_evalrounds. - hard_label_recovery_std: Standard deviation of HLR scores from
num_evalrounds. - improvement_over_random_mean: Mean of improvement over random scores from
num_evalrounds. - improvement_over_random_std: Standard deviation of improvement over random scores from
num_evalrounds. - label_robust_score_mean: Mean of LRS scores from
num_evalrounds. - label_robust_score_std: Standard deviation of LRS scores from
num_evalrounds.
Examples:
with config file:
>>> config = Config('/path/to/config.yaml')
>>> evaluator = LabelRobustScoreHard(config=config)
# load the image and hard labels
>>> image_tensor, hard_labels = ...
# compute the metrics
>>> evaluator.compute_metrics(image_tensor=image_tensor, hard_labels=hard_labels)
# alternatively, you can provide the image path
>>> evaluator.compute_metrics(image_path='path/to/image/folder/', hard_labels=hard_labels)
with keyword arguments:
>>> evaluator = LabelRobustScoreHard(
... dataset='CIFAR10',
... real_data_path='./dataset/',
... ipc=10,
... model_name='ConvNet-3',
... data_aug_func='dsa',
... aug_params={
... "prob_flip": 0.5,
... "ratio_rotate": 15.0,
... "saturation": 2.0,
... "brightness": 1.0,
... "contrast": 0.5,
... "ratio_scale": 1.2,
... "ratio_crop_pad": 0.125,
... "ratio_cutout": 0.5
... },
... optimizer='sgd',
... lr_scheduler='step',
... weight_decay=0.0005,
... momentum=0.9,
... step_size=500,
... num_epochs=1000,
... real_batch_size=256,
... syn_batch_size=256,
... use_torchvision=False,
... eval_full_data=True,
... random_data_format='tensor',
... random_data_path='./random_data/',
... num_workers=4,
... save_path='./results/',
... use_zca=False,
... num_eval=5,
... device='cuda',
... dist=True
... )
# load the image and hard labels
>>> image_tensor, hard_labels = ...
# compute the metrics
>>> evaluator.compute_metrics(image_tensor=image_tensor, hard_labels=hard_labels)
# alternatively, you can provide the image path
>>> evaluator.compute_metrics(image_path='path/to/image/folder/', hard_labels=hard_labels)
LabelRobustScoreSoft
CLASS dd_ranking.metrics.LabelRobustScoreSoft(config: Optional[Config] = None, dataset: str = 'CIFAR10', real_data_path: str = './dataset/', ipc: int = 10, model_name: str = 'ConvNet-3', soft_label_mode: str='S', soft_label_criterion: str='kl', loss_fn_kwargs: dict=None, data_aug_func: str='cutmix', aug_params: dict={'cutmix_p': 1.0}, optimizer: str='sgd', lr_scheduler: str='step', weight_decay: float=0.0005, momentum: float=0.9, step_size: int=None, num_eval: int=5, im_size: tuple=(32, 32), num_epochs: int=300, use_zca: bool=False, use_aug_for_hard: bool=False, random_data_format: str='tensor', random_data_path: str=None, real_batch_size: int=256, syn_batch_size: int=256, save_path: str=None, eval_full_data: bool=False, stu_use_torchvision: bool=False, tea_use_torchvision: bool=False, num_workers: int=4, teacher_dir: str='./teacher_models', teacher_model_names: list=None, custom_train_trans: Optional[Callable]=None, custom_val_trans: Optional[Callable]=None, device: str="cuda", dist: bool=False ) [SOURCE]
A class for evaluating the performance of a dataset distillation method with soft labels. User is able to modify the attributes as needed.
Parameters
- config(Optional[Config]): Config object for specifying all attributes. See config for more details.
- dataset(str): Name of the real dataset.
- real_data_path(str): Path to the real dataset.
- ipc(int): Images per class.
- model_name(str): Name of the surrogate model. See models for more details.
- soft_label_mode(str): Number of soft labels per image.
Sfor single soft label,Mfor multiple soft labels. - soft_label_criterion(str): Loss function for using soft labels. Currently supports
klfor KL divergence,scefor soft cross-entropy, andmse_gtfor MSEGT loss introduced in EDC. - loss_fn_kwargs(dict): Keyword arguments for the loss function.
temperatureandscale_lossfor KL and SCE loss, andmse_weightandce_weightfor MSE and CE loss. - data_aug_func(str): Data augmentation function used during training. Currently supports
dsa,cutmix,mixup. See augmentations for more details. - aug_params(dict): Parameters for the data augmentation function.
- use_aug_for_hard(bool): Whether to use the data augmentation specified in
data_aug_funcfor hard label evaluation. - optimizer(str): Name of the optimizer. Currently supports torch-based optimizers -
sgd,adam, andadamw. - lr_scheduler(str): Name of the learning rate scheduler. Currently supports torch-based schedulers -
step,cosine,lambda_step, andcosineannealing. - weight_decay(float): Weight decay for the optimizer.
- momentum(float): Momentum for the optimizer.
- step_size(int): Step size for the learning rate scheduler.
- use_zca(bool): Whether to use ZCA whitening.
- num_eval(int): Number of evaluations to perform.
- im_size(tuple): Size of the images.
- num_epochs(int): Number of epochs to train.
- real_batch_size(int): Batch size for the real dataset.
- syn_batch_size(int): Batch size for the synthetic dataset.
- stu_use_torchvision(bool): Whether to use torchvision to initialize the student model.
- tea_use_torchvision(bool): Whether to use torchvision to initialize the teacher model.
- teacher_dir(str): Path to the teacher model.
- teacher_model_names(list): List of teacher model names.
- random_data_format(str): Format of the random data,
tensororimage. - random_data_path(str): Path to save the random data.
- eval_full_data(bool): Whether to compute the test accuracy on the full dataset (might be time-consuming on large datasets such as ImageNet1K, so we have provided a full dataset performance cache).
- num_workers(int): Number of workers for data loading.
- save_path(Optional[str]): Path to save the results.
- custom_train_trans(Optional[Callable]): Custom transformation function when loading synthetic data. Only support torchvision transformations. See torchvision-based transformations for more details.
- custom_val_trans(Optional[Callable]): Custom transformation function when loading test dataset. Only support torchvision transformations. See torchvision-based transformations for more details.
- device(str): Device to use for evaluation,
cudaorcpu. - dist(bool): Whether to use distributed training.
Methods
compute_metrics(image_tensor: Tensor = None, image_path: str = None, soft_labels: Tensor = None, syn_lr: float = None, lrs_lambda: float = 0.5)
- Compute the test accuracy of the surrogate model on the synthetic dataset under hard labels. We perform learning rate tuning for the best performance.
- Compute the test accuracy of the surrogate model on the real dataset under the same setting as step 1.
- Compute the test accuracy of the surrogate model on the synthetic dataset under soft labels.
- Compute the test accuracy of the surrogate model on the randomly selected dataset under the same setting as step 3.
- Compute the HLR and IOR scores.
- Compute the LRS.
The final scores are the average of the scores from num_eval rounds.
Parameters
- image_tensor(Tensor): Image tensor. Must specify when
image_pathis not provided. We require the shape to be(N x IPC, C, H, W)whereNis the number of classes. - image_path(str): Path to the image. Must specify when
image_tensoris not provided. - soft_labels(Tensor): Soft label tensor. Must specify when
soft_label_modeisS. The first dimension must be the same asimage_tensor. - syn_lr(float): Learning rate for the synthetic dataset. If not specified, the learning rate will be tuned automatically.
- lrs_lambda(float): Weighting parameter for the LRS.
Returns
A dictionary with the following keys:
- hard_label_recovery_mean: Mean of HLR scores from
num_evalrounds. - hard_label_recovery_std: Standard deviation of HLR scores from
num_evalrounds. - improvement_over_random_mean: Mean of improvement over random scores from
num_evalrounds. - improvement_over_random_std: Standard deviation of improvement over random scores from
num_evalrounds. - label_robust_score_mean: Mean of LRS from
num_evalrounds. - label_robust_score_std: Standard deviation of LRS from
num_evalrounds.
Examples
with config file:
>>> config = Config('/path/to/config.yaml')
>>> evaluator = LabelRobustScoreSoft(config=config)
# load image and soft labels
>>> image_tensor, soft_labels = ...
# compute metrics
>>> evaluator.compute_metrics(image_tensor=image_tensor, soft_labels=soft_labels)
# alternatively, provide image path
>>> evaluator.compute_metrics(image_path='path/to/image/folder/', soft_labels=soft_labels)
with keyword arguments:
>>> evaluator = LabelRobustScoreSoft(
... dataset='TinyImageNet',
... real_data_path='./dataset/',
... ipc=10,
... model_name='ResNet-18-BN',
... soft_label_mode='M',
... soft_label_criterion='kl',
... loss_fn_kwargs={
... "temperature": 30.0,
... "scale_loss": False,
... },
... data_aug_func='mixup',
... aug_params={
... "mixup_p": 0.8,
... },
... optimizer='sgd',
... lr_scheduler='step',
... num_epochs=300,
... step_size=100,
... weight_decay=0.0005,
... momentum=0.9,
... use_zca=False,
... use_aug_for_hard=False,
... stu_use_torchvision=True,
... tea_use_torchvision=True,
... num_workers=4,
... save_path='./results',
... eval_full_data=False,
... random_data_format='image',
... random_data_path='./random_data',
... num_eval=5,
... device='cuda'
... )
# load image and soft labels
>>> image_tensor, soft_labels = ...
# compute metrics
>>> evaluator.compute_metrics(image_tensor=image_tensor, soft_labels=soft_labels)
# alternatively, provide image path
>>> evaluator.compute_metrics(image_path='path/to/image/folder/', soft_labels=soft_labels)
AugmentationRobustScore
CLASS dd_ranking.metrics.AugmentationRobustScore(config: Optional[Config] = None, dataset: str = 'ImageNet1K', real_data_path: str = './dataset/', ipc: int = 10, model_name: str = 'ResNet-18-BN', label_type: str = 'soft', soft_label_mode: str='S', soft_label_criterion: str='kl', loss_fn_kwargs: dict=None, data_aug_func: str='cutmix', aug_params: dict={'cutmix_p': 1.0}, optimizer: str='sgd', lr_scheduler: str='step', weight_decay: float=0.0005, momentum: float=0.9, step_size: int=None, num_eval: int=5, im_size: tuple=(224, 224), num_epochs: int=300, use_zca: bool=False, random_data_format: str='image', random_data_path: str=None, batch_size: int=256, save_path: str=None, stu_use_torchvision: bool=False, tea_use_torchvision: bool=False, num_workers: int=4, teacher_dir: str='./teacher_models', teacher_model_names: list=None, custom_train_trans: Optional[Callable]=None, custom_val_trans: Optional[Callable]=None, device: str="cuda", dist: bool=False ) [SOURCE]
A class for evaluating the performance of a dataset distillation method with soft labels. User is able to modify the attributes as needed.
Parameters
- config(Optional[Config]): Config object for specifying all attributes. See config for more details.
- dataset(str): Name of the real dataset.
- real_data_path(str): Path to the real dataset.
- ipc(int): Images per class.
- model_name(str): Name of the surrogate model. See models for more details.
- label_type(str): Type of label representation.
softfor soft labels,hardfor hard labels. - soft_label_mode(str): Number of soft labels per image.
Sfor single soft label,Mfor multiple soft labels. - soft_label_criterion(str): Loss function for using soft labels. Currently supports
klfor KL divergence,scefor soft cross-entropy, andmse_gtfor MSEGT loss introduced in EDC. - loss_fn_kwargs(dict): Keyword arguments for the loss function, e.g.
temperatureandscale_lossfor KL and SCE loss, andmse_weightandce_weightfor MSEGT loss. - data_aug_func(str): Data augmentation function used during training. Currently supports
dsa,cutmix,mixup. See augmentations for more details. - aug_params(dict): Parameters for the data augmentation function.
- optimizer(str): Name of the optimizer. Currently supports torch-based optimizers -
sgd,adam, andadamw. - lr_scheduler(str): Name of the learning rate scheduler. Currently supports torch-based schedulers -
step,cosine,lambda_step, andcosineannealing. - weight_decay(float): Weight decay for the optimizer.
- momentum(float): Momentum for the optimizer.
- step_size(int): Step size for the learning rate scheduler.
- use_zca(bool): Whether to use ZCA whitening.
- num_eval(int): Number of evaluations to perform.
- im_size(tuple): Size of the images.
- num_epochs(int): Number of epochs to train.
- batch_size(int): Batch size for the model training.
- stu_use_torchvision(bool): Whether to use torchvision to initialize the student model.
- tea_use_torchvision(bool): Whether to use torchvision to initialize the teacher model.
- teacher_dir(str): Path to the teacher model.
- teacher_model_names(list): List of teacher model names.
- random_data_format(str): Format of the random data,
tensororimage. - random_data_path(str): Path to save the random data.
- num_workers(int): Number of workers for data loading.
- save_path(Optional[str]): Path to save the results.
- custom_train_trans(Optional[Callable]): Custom transformation function when loading synthetic data. Only support torchvision transformations. See torchvision-based transformations for more details.
- custom_val_trans(Optional[Callable]): Custom transformation function when loading test dataset. Only support torchvision transformations. See torchvision-based transformations for more details.
- device(str): Device to use for evaluation,
cudaorcpu. - dist(bool): Whether to use distributed training.
Methods
compute_metrics(image_tensor: Tensor = None, image_path: str = None, soft_labels: Tensor = None, syn_lr: float = None, ars_lambda: float = 0.5)
- Compute the test accuracy of the surrogate model on the synthetic dataset without data augmentation.
- Compute the test accuracy of the surrogate model on the synthetic dataset with data augmentation.
- Compute the test accuracy of the surrogate model on the randomly selected dataset without data augmentation. We perform learning rate tuning for the best performance.
- Compute the test accuracy of the surrogate model on the randomly selected dataset with data augmentation. We perform learning rate tuning for the best performance.
- Compute the ARS score.
The final scores are the average of the scores from num_eval rounds.
Parameters
- image_tensor(Tensor): Image tensor. Must specify when
image_pathis not provided. We require the shape to be(N x IPC, C, H, W)whereNis the number of classes. - image_path(str): Path to the image. Must specify when
image_tensoris not provided. - soft_labels(Tensor): Soft label tensor. Must specify when
soft_label_modeisS. The first dimension must be the same asimage_tensor. - syn_lr(float): Learning rate for the synthetic dataset. If not specified, the learning rate will be tuned automatically.
- ars_lambda(float): Weighting parameter for the ARS.
Returns
A dictionary with the following keys:
- with_aug_mean: Mean of test accuracy scores with data augmentation from
num_evalrounds. - with_aug_std: Standard deviation of test accuracy scores with data augmentation from
num_evalrounds. - without_aug_mean: Mean of test accuracy scores without data augmentation from
num_evalrounds. - without_aug_std: Standard deviation of test accuracy scores without data augmentation from
num_evalrounds. - augmentation_robust_score_mean: Mean of ARS scores from
num_evalrounds. - augmentation_robust_score_std: Standard deviation of ARS scores from
num_evalrounds.
Examples
with config file:
>>> config = Config('/path/to/config.yaml')
>>> evaluator = AugmentationRobustScore(config=config)
# load image and soft labels
>>> image_tensor, soft_labels = ...
# compute metrics
>>> evaluator.compute_metrics(image_tensor=image_tensor, soft_labels=soft_labels)
# alternatively, provide image path
>>> evaluator.compute_metrics(image_path='path/to/image/folder/', soft_labels=soft_labels)
with keyword arguments:
>>> evaluator = AugmentationRobustScore(
... dataset='ImageNet1K',
... real_data_path='./dataset/',
... ipc=10,
... model_name='ResNet-18-BN',
... label_type='soft',
... soft_label_mode='M',
... soft_label_criterion='kl',
... loss_fn_kwargs={
... "temperature": 30.0,
... "scale_loss": False,
... },
... data_aug_func='mixup',
... aug_params={
... "mixup_p": 0.8,
... },
... optimizer='adamw',
... lr_scheduler='cosine',
... num_epochs=300,
... weight_decay=0.0005,
... momentum=0.9,
... use_zca=False,
... stu_use_torchvision=True,
... tea_use_torchvision=True,
... num_workers=4,
... save_path='./results',
... random_data_format='image',
... random_data_path='./random_data',
... teacher_dir='./teacher_models',
... teacher_model_names=['ResNet-18-BN'],
... num_eval=5,
... device='cuda'
... )
# load image and soft labels
>>> image_tensor, soft_labels = ...
# compute metrics
>>> evaluator.compute_metrics(image_tensor=image_tensor, soft_labels=soft_labels)
# alternatively, provide image path
>>> evaluator.compute_metrics(image_path='path/to/image/folder/', soft_labels=soft_labels)
GeneralEvaluator
CLASS dd_ranking.metrics.GeneralEvaluator(config: Optional[Config] = None, dataset: str = 'CIFAR10', real_data_path: str = './dataset/', ipc: int = 10, model_name: str = 'ConvNet-3', soft_label_mode: str='S', soft_label_criterion: str='kl', temperature: float=1.0, data_aug_func: str='cutmix', aug_params: dict={'cutmix_p': 1.0}, optimizer: str='sgd', lr_scheduler: str='step', weight_decay: float=0.0005, momentum: float=0.9, num_eval: int=5, im_size: tuple=(32, 32), num_epochs: int=300, use_zca: bool=False, real_batch_size: int=256, syn_batch_size: int=256, default_lr: float=0.01, save_path: str=None, stu_use_torchvision: bool=False, tea_use_torchvision: bool=False, num_workers: int=4, teacher_dir: str='./teacher_models', custom_train_trans: Optional[Callable]=None, custom_val_trans: Optional[Callable]=None, device: str="cuda" ) [SOURCE]
A class for evaluating the traditional test accuracy of a surrogate model on the synthetic dataset under various settings (label type, data augmentation, etc.).
Parameters
Same as Soft Label Evaluator.
Methods
compute_metrics(image_tensor: Tensor = None, image_path: str = None, labels: Tensor = None, syn_lr: float = None)
Parameters
- image_tensor(Tensor): Image tensor. Must specify when
image_pathis not provided. We require the shape to be(N x IPC, C, H, W)whereNis the number of classes. - image_path(str): Path to the image. Must specify when
image_tensoris not provided. - labels(Tensor): Label tensor. It can be either hard labels or soft labels. When
soft_label_mode=S, the label tensor must be provided. - syn_lr(float): Learning rate for the synthetic dataset. If not specified, the learning rate will be tuned automatically.
Returns
A dictionary with the following keys:
- acc_mean: Mean of test accuracy from
num_evalrounds. - acc_std: Standard deviation of test accuracy from
num_evalrounds.
Examples
with config file:
>>> config = Config('/path/to/config.yaml')
>>> evaluator = GeneralEvaluator(config=config)
# load image and labels
>>> image_tensor, labels = ...
# compute metrics
>>> evaluator.compute_metrics(image_tensor=image_tensor, labels=labels)
# alternatively, provide image path
>>> evaluator.compute_metrics(image_path='path/to/image.jpg', labels=labels)
with keyword arguments:
>>> evaluator = GeneralEvaluator(
... dataset='CIFAR10',
... model_name='ConvNet-3',
... soft_label_mode='S',
... soft_label_criterion='sce',
... temperature=1.0,
... data_aug_func='cutmix',
... aug_params={
... "cutmix_p": 1.0,
... },
... optimizer='sgd',
... lr_scheduler='step',
... weight_decay=0.0005,
... momentum=0.9,
... stu_use_torchvision=False,
... tea_use_torchvision=False,
... num_eval=5,
... device='cuda'
... )
# load image and labels
>>> image_tensor, labels = ...
# compute metrics
>>> evaluator.compute_metrics(image_tensor=image_tensor, labels=labels)
# alternatively, provide image path
>>> evaluator.compute_metrics(image_path='path/to/image.jpg', labels=labels)
Augmentations
DD-Ranking supports commonly used data augmentations in existing methods. A list of augmentations is provided below:
In DD-Ranking, data augmentations are specified when initializing an evaluator. The following arguments are related to data augmentations:
- data_aug_func(str): The name of the data augmentation function used during training. Currently, we support
dsa,mixup,cutmix. - aug_params(dict): The parameters for the data augmentation function.
- custom_train_trans(torchvision.transforms.Compose): The custom train transform used to load the synthetic data when it's in '.jpg' or '.png' format.
- custom_val_trans(torchvision.transforms.Compose): The custom val transform used to load the test dataset.
- use_zca(bool): Whether to use ZCA whitening for the data augmentation. This is only applicable to methods that use ZCA whitening during distillation.
# When initializing an evaluator, the data augmentation function is specified.
>>> evaluator = SoftLabelEvaluator(
...
data_aug_func=..., # Specify the data augmentation function
aug_params=..., # Specify the parameters for the data augmentation function
custom_train_trans=..., # Specify the custom train transform
custom_val_trans=..., # Specify the custom val transform
use_zca=..., # Specify whether to use ZCA whitening
...
)
Differentiable Siamese Augmentation (DSA)
DSA is one of differentiable data augmentations, first used in the dataset distillation task by DSA. Our implementation of DSA is adopted from DSA. It supports the following differentiable augmentations:
- Random Flip
- Random Rotation
- Random Saturation
- Random Brightness
- Random Contrast
- Random Scale
- Random Crop
- Random Cutout
CLASS ddranking.aug.DSA(params: dict, seed: int, aug_mode: str) [SOURCE]
Parameters
- params(dict): Parameters for the DSA augmentations. We require the parameters to be in the format of
{'param_name': param_value}. For example,{'flip': 0.5, 'rotate': 15.0, 'scale': 1.2, 'crop': 0.125, 'cutout': 0.5, 'brightness': 1.0, 'contrast': 0.5, 'saturation': 2.0}. - seed(int): Random seed. Default is
-1. - aug_mode(str):
Sfor randomly selecting one augmentation for each batch.Mfor applying all augmentations for each batch.
Example
# When intializing an evaluator with DSA augmentation, and DSA object will be constructed.
>>> self.aug_func = DSA(params={'flip': 0.5, 'rotate': 15.0, 'scale': 1.2, 'crop': 0.125, 'cutout': 0.5, 'brightness': 1.0, 'contrast': 0.5, 'saturation': 2.0}, seed=-1, aug_mode='S')
# During training, the DSA object will be used to augment the data.
>>> images = aug_func(images)
Cutmix
Cutmix is a data augmentation technique that creates new samples by combining patches from two images while blending their labels proportionally to the area of the patches.. We follow the implementation of cutmix in SRe2L.
CLASS ddranking.aug.Cutmix(params: dict) [SOURCE]
Parameters
- params(dict): Parameters for the cutmix augmentation. We require the parameters to be in the format of
{'param_name': param_value}. For cutmix, onlybeta(beta distribution parameter) needs to be specified, e.g.{'beta': 1.0}.
Example
# When intializing an evaluator with cutmix augmentation, and cutmix object will be constructed.
>>> self.aug_func = Cutmix(params={'beta': 1.0})
# During training, the cutmix object will be used to augment the data.
>>> images = aug_func(images)
Mixup
Mixup is a data augmentation technique that generates new training samples by linearly interpolating pairs of images. We follow the implementation of mixup in SRe2L.
CLASS ddranking.aug.Mixup(params: dict) [SOURCE]
Parameters
- params(dict): Parameters for the mixup augmentation. We require the parameters to be in the format of
{'param_name': param_value}. For mixup, onlylambda(mixup strength) needs to be specified, e.g.{'lambda': 0.8}.
Example
# When intializing an evaluator with mixup augmentation, and mixup object will be constructed.
>>> self.aug_func = Mixup(params={'lambda': 0.8})
# During training, the mixup object will be used to augment the data.
>>> images = aug_func(images)
Models
DD-Ranking provides the implementation of a set of commonly used model architectures in existing dataset distillation methods. Users can flexibly use these models for main evaluation or cross-architecture evaluation. We will keep updating this section with more models.
Users can also define any model with torchvision.
Naming Convention
We use the following naming conventions for models in DD-Ranking:
model name - model depth - norm type(for DD-Ranking implemented models)- torchvision model names, e.g.
vgg11andvit_b_16
Model name and depth are required when not using tochvision. When norm type is not specified, we use default normalization for the model. For example, ResNet-18-BN means ResNet18 with batch normalization. ConvNet-4 means ConvNet with depth 4 and default instance normalization.
Pretrained Model Weights
For users' convenience, we provide pretrained model weights on CIFAR10, CIFAR100, and TinyImageNet for the following models:
- ConvNet-3 (CIFAR10, CIFAR100)
- ConvNet-3-BN (CIFAR10, CIFAR100)
- ConvNet-4 (TinyImageNet)
- ConvNet-4-BN (TinyImageNet)
- ResNet-18-BN (CIFAR10, CIFAR100, TinyImageNet, ImageNet1K)
Users can download the weights from the following links: Pretrained Model Weights.
Users can also feel free to use torchvision pretrained models.
ConvNet
Our implementation of ConvNet is based on DC.
By default, we use width 128, average pooling, and ReLU activation. We provide the following interface to initialize a ConvNet model:
dd_ranking.utils.get_convnet(model_name: str, im_size: tuple, channel: int, num_classes: int, net_depth: int, net_norm: str, pretrained: bool, model_path: str) [SOURCE]
Parameters
- model_name(str): Name of the model. Please navigate to models for the model naming convention in DD-Ranking.
- im_size(tuple): Image size.
- channel(int): Number of channels of the input image.
- num_classes(int): Number of classes.
- net_depth(int): Depth of the network.
- net_norm(str): Normalization method. In ConvNet, we support
instance,batch, andgroupnormalization. - pretrained(bool): Whether to load pretrained weights.
- model_path(str): Path to the pretrained model weights.
To load a ConvNet model with different width or activation function or pooling method, you can use the following interface:
dd_ranking.utils.networks.ConvNet(channel, num_classes, net_width, net_depth, net_act, net_norm, net_pooling, im_size) [SOURCE]
Parameters
We only list the parameters that are not present in get_convnet.
- net_width(int): Width of the network.
- net_act(str): Activation function. We support
relu,leakyrelu, andsigmoid. - net_pooling(str): Pooling method. We support
avgpooling,maxpooling, andnone.
AlexNet
Our implementation of ConvNet is based on DC.
We provide the following interface to initialize a AlexNet model:
ddranking.utils.get_alexnet(model_name: str, im_size: tuple, channel: int, num_classes: int, pretrained: bool, model_path: str) [SOURCE]
Parameters
- model_name(str): Name of the model. Please navigate to models for the model naming convention in DD-Ranking.
- im_size(tuple): Image size.
- channel(int): Number of channels of the input image.
- num_classes(int): Number of classes.
- pretrained(bool): Whether to load pretrained weights.
- model_path(str): Path to the pretrained model weights.
ResNet
DD-Ranking supports implementation of ResNet in both DC and torchvision.
We provide the following interface to initialize a ConvNet model:
ddranking.utils.get_resnet(model_name: str, im_size: tuple, channel: int, num_classes: int, depth: int, batchnorm: bool, use_torchvision: bool, pretrained: bool, model_path: str) [SOURCE]
Parameters
- model_name(str): Name of the model. Please navigate to models for the model naming convention in DD-Ranking.
- im_size(tuple): Image size.
- channel(int): Number of channels of the input image.
- num_classes(int): Number of classes.
- depth(int): Depth of the network.
- batchnorm(bool): Whether to use batch normalization.
- use_torchvision(bool): Whether to use torchvision to initialize the model. When using torchvision, the ResNet model uses batch normalization by default.
- pretrained(bool): Whether to load pretrained weights.
- model_path(str): Path to the pretrained model weights.
model.conv1 = torch.nn.Conv2d(3, 64, kernel_size=(3,3), stride=(1,1), padding=(1,1), bias=False)
model.maxpool = torch.nn.Identity()
LeNet
Our implementation of LeNet is based on DC.
We provide the following interface to initialize a LeNet model:
ddranking.utils.get_lenet(model_name: str, im_size: tuple, channel: int, num_classes: int, pretrained: bool, model_path: str) [SOURCE]
Parameters
- model_name(str): Name of the model. Please navigate to models for the model naming convention in DD-Ranking.
- im_size(tuple): Image size.
- channel(int): Number of channels of the input image.
- num_classes(int): Number of classes.
- pretrained(bool): Whether to load pretrained weights.
- model_path(str): Path to the pretrained model weights.
VGG
DD-Ranking supports implementation of VGG in both DC and torchvision.
We provide the following interface to initialize a ConvNet model:
ddranking.utils.get_vgg(model_name: str, im_size: tuple, channel: int, num_classes: int, depth: int, batchnorm: bool, use_torchvision: bool, pretrained: bool, model_path: str) [SOURCE]
Parameters
- model_name(str): Name of the model. Please navigate to models for the model naming convention in DD-Ranking.
- im_size(tuple): Image size.
- channel(int): Number of channels of the input image.
- num_classes(int): Number of classes.
- depth(int): Depth of the network.
- batchnorm(bool): Whether to use batch normalization.
- use_torchvision(bool): Whether to use torchvision to initialize the model.
- pretrained(bool): Whether to load pretrained weights.
- model_path(str): Path to the pretrained model weights.
For 32x32 image size:
model.classifier = nn.Sequential(OrderedDict([
('fc1', nn.Linear(512 * 1 * 1, 4096)),
('relu1', nn.ReLU(True)),
('drop1', nn.Dropout()),
('fc2', nn.Linear(4096, 4096)),
('relu2', nn.ReLU(True)),
('drop2', nn.Dropout()),
('fc3', nn.Linear(4096, num_classes)),
]))
For 64x64 image size:
model.classifier = nn.Sequential(OrderedDict([
('fc1', nn.Linear(512 * 2 * 2, 4096)),
('relu1', nn.ReLU(True)),
('drop1', nn.Dropout()),
('fc2', nn.Linear(4096, 4096)),
('relu2', nn.ReLU(True)),
('drop2', nn.Dropout()),
('fc3', nn.Linear(4096, num_classes)),
]))
MLP
Our implementation of MLP is based on DC.
We provide the following interface to initialize a MLP model:
ddranking.utils.get_mlp(model_name: str, im_size: tuple, channel: int, num_classes: int, pretrained: bool, model_path: str) [SOURCE]
Parameters
- model_name(str): Name of the model. Please navigate to models for the model naming convention in DD-Ranking.
- im_size(tuple): Image size.
- channel(int): Number of channels of the input image.
- num_classes(int): Number of classes.
- pretrained(bool): Whether to load pretrained weights.
- model_path(str): Path to the pretrained model weights.
Datasets
DD-Ranking provides a set of commonly used datasets in existing dataset distillation methods. Users can flexibly use these datasets for evaluation. The interface to load datasets is as follows:
ddranking.utils.get_dataset(dataset: str, data_path: str, im_size: tuple, use_zca: bool, custom_val_trans: Optional[Callable], device: str) [SOURCE]
Parameters
- dataset(str): Name of the dataset.
- data_path(str): Path to the dataset.
- im_size(tuple): Image size.
- use_zca(bool): Whether to use ZCA whitening. When set to True, the dataset will not be normalized using the mean and standard deviation of the training set.
- custom_train_trans(Optional[Callable]): Custom transformation on the training set.
- custom_val_trans(Optional[Callable]): Custom transformation on the validation set.
- device(str): Device for performing ZCA whitening.
Currently, we support the following datasets with default settings. We will keep updating this section with more datasets.
- CIFAR10
- channels:
3 - im_size:
(32, 32) - num_classes:
10 - mean:
[0.4914, 0.4822, 0.4465] - std:
[0.2023, 0.1994, 0.2010]
- channels:
- CIFAR100
- channels:
3 - im_size:
(32, 32) - num_classes:
100 - mean:
[0.4914, 0.4822, 0.4465] - std:
[0.2023, 0.1994, 0.2010]
- channels:
- TinyImageNet
- channels:
3 - im_size:
(64, 64) - num_classes:
200 - mean:
[0.485, 0.456, 0.406] - std:
[0.229, 0.224, 0.225]
- channels:
- ImageNet1K
- channels:
3 - im_size:
(224, 224) - num_classes:
1000 - mean:
[0.485, 0.456, 0.406] - std:
[0.229, 0.224, 0.225]
- channels:
Config
To ease the usage of DD-Ranking, we allow users to specify the parameters of the evaluator in a config file. The config file is a YAML file that contains the parameters of the evaluator. We illustrate the config file with the following examples.
LRS
dataset: CIFAR100 # dataset name
real_data_path: ./dataset/ # path to the real dataset
ipc: 10 # image per class
im_size: [32, 32] # image size
model_name: ResNet-18-BN # model name
stu_use_torchvision: true # whether to use torchvision to load student model
tea_use_torchvision: true # whether to use torchvision to load teacher model
teacher_dir: ./teacher_models # path to the pretrained teacher model
teacher_model_names: [ResNet-18-BN] # the list of teacher models being used for evaluation
data_aug_func: mixup # data augmentation function
aug_params:
lambda: 0.8 # data augmentation parameter; please follow this format for other parameters
use_zca: false # whether to use ZCA whitening
use_aug_for_hard: false # whether to use data augmentation for hard label evaluation
custom_train_trans: # custom torchvision-based transformations to process training data; please follow this format for your own transformations
- name: RandomCrop
args:
size: 32
padding: 4
- name: RandomHorizontalFlip
args:
p: 0.5
- name: ToTensor
- name: Normalize
args:
mean: [0.4914, 0.4822, 0.4465]
std: [0.2023, 0.1994, 0.2010]
custom_val_trans: null # custom torchvision-based transformations to process validation data; please follow the format above for your own transformations
soft_label_mode: M # soft label mode
soft_label_criterion: kl # soft label criterion
loss_fn_kwargs:
temperature: 30.0 # temperature for soft label
scale_loss: false # whether to scale the loss
optimizer: adamw # optimizer
lr_scheduler: cosine # learning rate scheduler
weight_decay: 0.01 # weight decay
momentum: 0.9 # momentum
num_eval: 5 # number of evaluations
eval_full_data: false # whether to compute the test accuracy on the full dataset
num_epochs: 400 # number of training epochs
num_workers: 4 # number of workers
device: cuda # device
dist: true # whether to use distributed training
syn_batch_size: 256 # batch size for synthetic data
real_batch_size: 256 # batch size for real data
save_path: ./results.csv # path to save the results
random_data_format: tensor # format of the random data, tensor or image
random_data_path: ./random_data # path to the save the random data
To use config file, you can follow the example below.
from dd_ranking.metrics import LabelRobustScoreSoft
config = Config(config_path='./config.yaml')
evaluator = LabelRobustScoreSoft(config)
ARS